Automated Data Superposition
Most methods for automated superposition of discrete data sets have two main components. First, they define a continuous interpolant for the data. Then, they define and minimize an objective function based on these interpolants.
The method used in this package (outlined here) uses Gaussian process regression to build statistical interpolants (that come with mean and variance estimates). The objective is the negative logarithm of the posterior probability that one data set is observed from the interpolant for another data set. Therefore, this method is an application of maximum a posteriori estimation.
Gaussian Process Regression
Gaussian Process Regression (GPR) is a machine learning method for building a continuous model of a data set. GPR treats each data point in a data set as observations \(y\) of (not necessarily independent) random variables. These random variables may be concatenated to form a random vector, or a stochastic process parameterized by the independent coordinate \(x\). If each random variable is assumed to follow a Gaussian distribution, then we call this a Gaussian Process:
The Gaussian Process model is defined by a mean function \(\mu(x)\), which is usually assumed to be zero, and a covariance kernel K(x,x’;theta), which defines the pointwise variance at \(x\) and pairwise covariance between \(x\) and \(x'\). We typically choose a form of the covariance kernel that encodes prior expectations about the data, such as some degree of smoothness, scale, or uncorrelated variance. The default kernel in this package is:
where the set of parameters \(\theta = [A, \alpha, l, B, \sigma]\) are called hyperparameters. The values of these hyperparameters are determined by maximizing the marginal log-likelihood of the data given the covariance kernel, with some prior specified over the hyperparameters.
Once the covariance kernel is set and hyperparameters are optimized, the posterior mean \(m(x)\) and variance \(s^2(x)\) of the Gaussian Process model are fixed:
where \(x^*\) is an arbitrary coordinate of interest, \(\underline{K}(x^*,\underline{x})\) is a vector obtained by evaluating the \(K(x^*,x';\theta)\) with \(x'\) taking on each value present in the data set, \(\mathbf{K}\) is a matrix obtained by evaluating \(K(x,x';\theta)\) with both \(x\) and \(x'\) taking on each value present in the data set, and \(\underline{y}\) is a vector consisting of each value of \(y\) present in the data set.
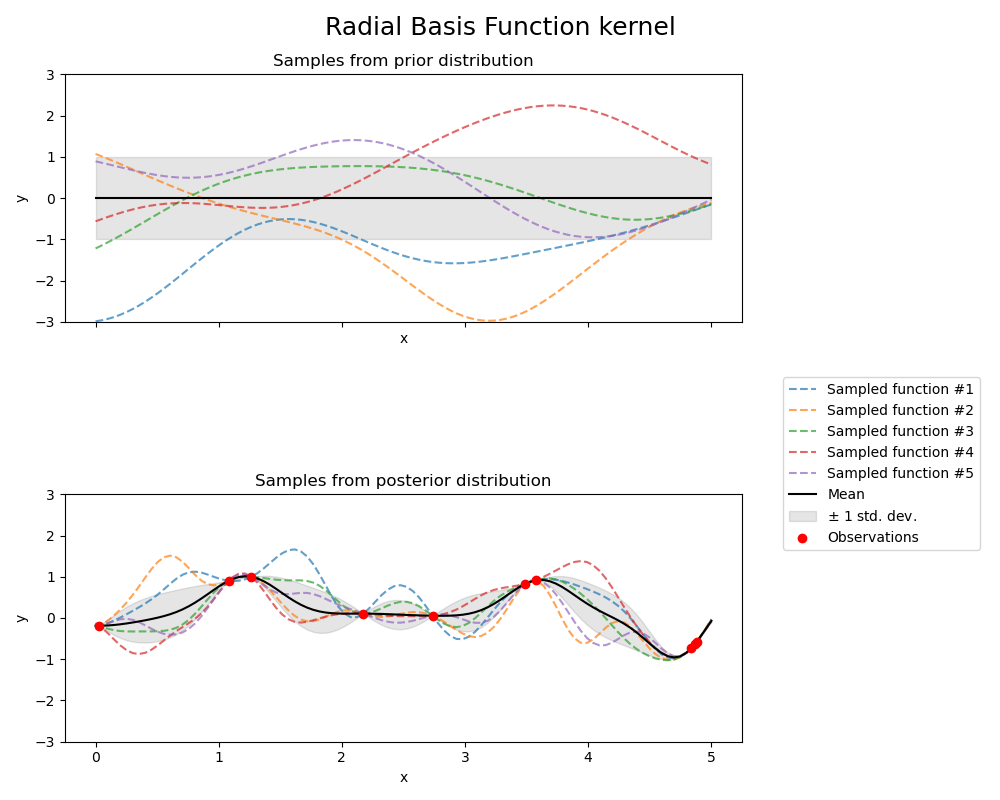
A trained Gaussian Process model predicts a smooth interpolant with uncertainty bounds, which looks qualitatively like the example presented below.

It is typical for GPR to be explained abstractly as specifying a prior distribution of functions that could represent a data set, and applying the data set to obtained the posterior distribution of functions drawn from that prior that are most likely to fit the data. For instance, the prior and posterior for a Radial Basis Function kernel (the first term in our kernel) with an example data set are presented below (taken from sklearn).
Maximum A Posteriori Estimation
Consider the problem of shifting a single data point \((x_i,y_i)\) by a horizontal scale factor \(a\) and a vertical shift factor \(b\). Say that this data point belongs to a data set at state \(j\), and we’d like to choose \(a\) and \(b\) so that this data point overlaps with a GP model from state \(k\). We begin by assuming that this shifted data point is an observation from the GP:
The negative log-likelihood (NLL) of this observation is:
Now, consider generalizing this task to an entire data set \(\mathcal{D}_j = \{(x_i, y_i)\}\). The NLL for this entire set is the sum of the NLLs of the individual data points:
Finally, to obtain the posterior probability of certain shift factors given the data, we apply Bayes’ theorem:
with a suitable choice of the prior over the shift factors, \(p(a,b)\). We typically employ either a uniform prior or a Gaussian prior, though others may be implemented within this package.
The maximum a posteriori estimate for the shift factors is that which minimizes the negative logarithm of the posterior:
By repeating this estimation for each consecutive pair of data sets, we may construct the master curve.